In the last article, I introduced the ETHICS dataset and the benchmark results of its 5 components for the BERT-base model. As a recap, the 5 components are: Justice, Virtue Ethics, Deontology, Utilitarianism, and Commonsense Morality. Now, in this article, we will cover the light weight versions of BERT, and then, we will use Ainize Workspace for training and evaluating all of the above mentioned components of the ETHICS dataset.
If you would like to check out the project right away, please refer to the link below!
- Github : GitHub - hendrycks/ethics: Aligning AI With Shared Human Values (ICLR 2021)
- Workspace : Ainize | Launchpad for open-source AI projects
- Workspace Github : GitHub - 589hero/ethics-benchmark
Since BERT (which is a transformer-based pre-trained language model) appeared in the field of natural language processing, the size of the model has increased exponentially. In particular, GPT-3, which appeared in 2020, has a whopping 175 billion parameters, and it is said that training costs about 12 million dollars. Therefore, as the size of the model increases, the cost for training increases as well, making it impossible to pre-train the model except for big enterprises who has the resources. Due to this, light weight versions to reduce the size of the model are being actively studied.
In this article, we will cover DistilBERT, ALBERT, and ELECTRA, which are BERT lightweight versions. Each of these three models reduced the size of the model or improved the training method in different ways. The first model we will introduce is DistilBERT.
DistilBERT
DistilBERT is a lightweight model of BERT that uses Knowledge Distillation. Knowledge distillation is a widely used method to make models lightweight, so that a small model (Student network) follows the distribution of a large model (Teacher Network) that has been trained well. By following this method, the goal to ensure that the performance of the small model is almost indistinguishable from that of the large model. During training, we use the output (vector) of the large model as the correct answer label for the small model from which to distill knowledge.
Now, what kind of Loss was used during DistilBERT’s pre-training process? According to the DistilBERT paper, three Losses were used.
The first is CrossEntropy Loss. The formula is the same as the general CrossEntropy Loss calculation, but the correct answer label is used as the output of the Teacher model, BERT. So, in the equation below, t_i is the output of the Teacher model, BERT, and s_i is the output of the Student model, DistilBERT.

Source : DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
The second is Masked Language Modeling Loss, which is also used for pre-training of BERT. This loss occurs in the process of predicting the masked token during pre-training.
The third is Cosine Embedding Loss. Using this loss, it is said that the direction of the hidden state vectors of the Teacher model and the Student model are aligned.
And in order to reduce the size of the model, DistilBERT Reduce the number of existing layers by half and deleted the token-type embeddings layer as well as the pooler layer. Therefore, NSP (Next Sentence Prediction) is not performed during training.
As a result, DistilBERT reduced the model size by 40% compared to BERT, and inference speed was 60% faster than BERT, but performance was maintained up to 97% of BERT.
ALBERT
ALBERT (A Lite BERT) is also a lightweight model of BERT. Even though the weight was reduced, its performance was measured higher than BERT’s performance. ALBERT carried out weight reduction using the following two methods.
The first method is factorized embedding parameterization, which means splitting a large matrix into two smaller matrices. Here, ALBERT splits the embedding layer through which the input tokens of ALBERT go into two. If the number of tokens is V and the dimension of the token embedding vector is H (hidden size), then the number of parameters of the embedding layer in the BERT is V x H . However, in ALBERT, WordPiece embedding size E is added, and the embedding layer of size V x H is decomposed into two matrices V x E and E x H.
If V=30000, H=768, E=128, the number of parameters in the embedding layer of BERT is V x H=30000 x 768=23040000, but in ALBERT, It is reduced to V x E+E x H=30000 x 128 + 128 x 768=3938304. Although the number of parameters is reduced, the dimension of the vector is the same as H after passing through the embedding layer.
The second method is cross-layer parameter sharing. Here, ALBERT shares parameters between embedding layers. So, it has the same effect as doing one embedding layer recursively. The encoding layer can be divided into an Attention part and a FFN (Feed Forward Network) part. It has been found that sharing only the parameters of the attention part of the encoding layer has higher performance than sharing all parameters or only the parameters of the FFN part.

Source : ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
As a result, using the above two methods, the number of parameters of the ALBERT-large model is 18 times less than that of the BERT-large model, and the training speed is 1.7 times faster.
Lastly, ALBERT changed the way to pre-train. In BERT, NSP (Next Sentence Prediction) is performed to determine whether two given sentences are consecutive. However, in a follow-up study of BERT, it was found that the size of the training effect was not large because the performance of NSP was not high, as it only covered one sentence at a time. Therefore, ALBERT performs Sentence Order Prediction (SOP), which predicts the order of multiple sentences instead of NSP.
ELECTRA
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) uses the structure of a GAN (Generative Adversarial Network) to improve the learning method in order to achieve faster learning.
The content related to ELECTRA has already been posted on the AI Network blog, so check out the article!
ETHICS Dataset benchmark using Ainize Workspace
Now, we will train and evaluate the ETHICS dataset using Ainize Workspace. You can create and use Workspace via Link. The model used bert-base-uncased (for comparison), distilbert-base-uncased, albert-base-v2, google/electra-base-discriminator uploaded on huggingface.

The benchmark results for each model are as follows.
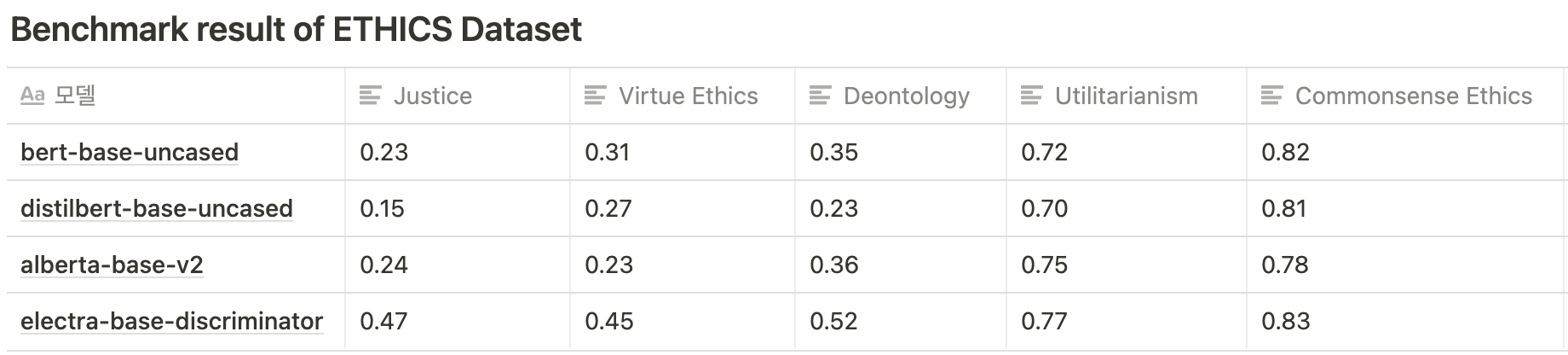
Although it is the result without hyperparameter tuning, the performance of ELECTRA was measured to be higher than that of BERT. It can be seen that changing the structure of the model using GAN led to a significant performance improvement.
So far, we have looked at the models with lightweight BERT and the ETHICS dataset benchmark result of each model. I wonder how many lightweight models will appear in the future. I’m also curious how the method to make lightweight model will affect the ethics of the model. What are your opinions? Share with others in the comments!