
Hello! I’m writing about an artificial intelligence model at a company, and I’d like to share it here. You can check out the article here!
Have you ever said something like, “Siri, set the alarm again in five minutes” when you want to sleep more? While watching the YouTube video, you may have seen at least once that the comment, “Unknown YouTube algorithm dragged me here,” received high sympathy and was recorded at the top.
This is the time when we cannot discuss our lives except ‘AI’. We are having days of growing interest in AI and data. There are many people who are interested in related fields, but have difficulties in how to get information and share experiences. For those people, I’m going to organize the contents and share them in a series.
The first AI model I will introduce is “Hyunwoongko’s Open chat”.
Hyunwoongko is currently working at Kakao Brain and researching natural language processing at a startup called TUNiB. This model allows you to easily access open domain chatbots based on BlenderBot and DialoGPT which allow you to have conversations with artificial intelligence with just 3 lines of code. (You can easily install it with pip install openchat .)
If you would like to check the project right away, please refer to the following link.
Github: https://github.com/hyunwoongko/openchat
DEMO: https://main-openchat-fpem123.endpoint.ainize.ai/
API: https://ainize.ai/fpem123/openchat
Colab: https://colab.research.google.com/drive/1rGw2GINWgLwQYkp0KWT4P6U2ci5pJ862#scrollTo=1A-PezpTwnI5

Do you feel that this conversation is awkward? These lines are part of a conversation using openchat. In other words, this conversation was not held amongst people, it was made using artificial intelligence. It is still impossible for humans to communicate freely with artificial intelligence like Jarvis in the movie Iron Man, but as the technology of artificial intelligence has evolved rapidly over the past few years, artificial intelligence has improved to reach the level of such simple communication with humans.
What is a chatbot?
A chatbot is literally a robot designed to talk. In simple words, it’s a form of artificial intelligence that interprets the additional information which describes the intention in a given sentence, such as when people communicate and provide an appropriate response to the conversation being held. The intention is the purpose or goal, and the additional information describing the intention is called an entity. For example, in the sentence ‘Shall we eat dinner at 6 o’clock tomorrow?’, the intent is ‘Shall we eat dinner?’ and the entity refers to the additional information that describes the intention, so the entity can be seen as ‘tomorrow, night, 6 o’clock’. Chatbots need to use intents and entities in order to provide appropriate responses.
History of chatbots
What comes to your mind when you think of ‘Siri’? Twenty years ago, you might have associated the name “Siri” among your friends or acquaintances, but now Apple will surely come to mind. Siri is one of the chatbots we’ve described so far today. The starting point of this chatbot seems to be ELIZA, which was developed in 1966 by the MIT Artificial Intelligence Lab. At this time, ELIZA used a simple pattern matching technique and it used to be just an early developed artificial intelligence. Now, when Siri was released in 2011, there were issues about the usefulness of Siri, but its ability to grasp the context of the conversation was amazing and it was the inspiration behind the movement to apply chatbots to everyday life. Over time, with the advent of AlphaGo, artificial intelligence has been attracting attention, and interest in artificial intelligence models that can naturally process language has increased, and natural language processing models have developed a lot. Accordingly, models such as GPT and BERT were introduced, and the parameters of these models were fine-tuned to suit a new purpose, further enhancing the chatbot’s performance. The future growth potential of chatbots is expected to be very high.

What model was used in Open chat?
In Open chat, you can choose a few language models such as “BlenderBot” or “DialoGPT” to have a conversation. In this case, the language model is a model that calculates and learns numerically how natural the language provided by any given person as training data, and assigns probability means. Let’s take a look at the features of both models.
Shall we blend the data? : BlenderBot
BlenderBot is an open domain chatbot model announced by Facebook. BlenderBot used in openchat has 4 models with different number of parameters, each with 90M(small), 400M(medium), 1B(large), and 3B(xlarge) parameters. Pre-learning was conducted with the Fairseq toolkit, an NLP framework developed by Facebook AI Research, and the pre-learning data set was conducted with articles that match the conditions among articles written in Reddit. For fine-tuning, we used the ParlAI toolkit developed by Facebook AI Research, which provides a variety of chatbot models, training, and data sets. The datasets used in fine tuning are: ConvAI2 (data set related to personality), Empathetic Dialogues (data set related to empathy), Wizard of Wikipedia (data set related to knowledge) and Blended Skill Talk (mixed data set presented earlier). By using Blended Skill Talk, this model helps to maintain learning outcomes from previous datasets (ConvAI2, Wizard of Wikipedia, Empathetic Dialogues). Detailed information about the model can be found in Here.
To briefly summarize this model
- Chatbot model announced by Facebook
- Use of Fairseq toolkit and ParlAI toolkit
- Use of data that meets the conditions among the articles written on Reddit + ConvAI2 + Empathetic Dialogues + Wizard of Wikipedia + Blended Skill Talk as learning data
Let’s change it slightly in GPT2: DialoGPT
DialoGPT is a chatbot model announced by Microsoft. As the name implies, it is designed based on the architecture of GPT-2, and it is a model that has been transformed to fit into a conversational format. DialoGPT used in openchat has three models with different number of parameters, each with 117M(small), 345M(medium), and 762M(large) parameters, which is smaller than the number of BlenderBot parameters. The data set used for training was filtered out of the articles written on Reddit from 2005 to 2017, and then used for training. Also, there is a URL in the source or target when the target has at least 3 word repetitions, and when none of the top 50 (a, the, of …) frequently appearing English words are included (determined in a foreign language). These conditions and such containing aggressive words, became filtering conditions and were not used for learning. After filtering, about 140 million conversations were formed. Detailed information about the model can be found in here.
To briefly summarize this model
- Chatbot model announced by Microsoft
- Transformed from GPT2’s model to match the dialogue
- Crawl only data that meets the conditions among articles written on Reddit and use them as learning data
“A dwarf on a giant’s shoulders sees farther of the two.” — George Herbert
In order to use a chatbot like the above, you need to look at the paper that introduces the model and design the code according to the method presented in such paper. You also need to get the data to train the model, and prepare the GPU to create a learning environment. I particularly find the above method inefficient for a task that requires a lot of time and effort to be invested but we can easily see the big picture with the help of the open source giant. Since many open source developers distribute their results as open source on behalf of their work, using a chatbot distributed as open source makes it easier to use the chatbot. Loads of sites distributing open source include GitHub, Hugging Face, Ainize, and more. Hugging Face is an AI community with models provided on Facebook, Google, and Natural Language Processing (NLP) libraries as open source in a small offer. Ainize is a service that provides various functions for open source, such as distributing open source AI projects and converting open source code to extensible API services.
So how do you use it?
- Using pip install Open chat (The method described in the article is based on openchat version 1.0.)
First, install Open chat, then enter the desired model and size as parameters, and run it, at this point you will be able to use Open chat.
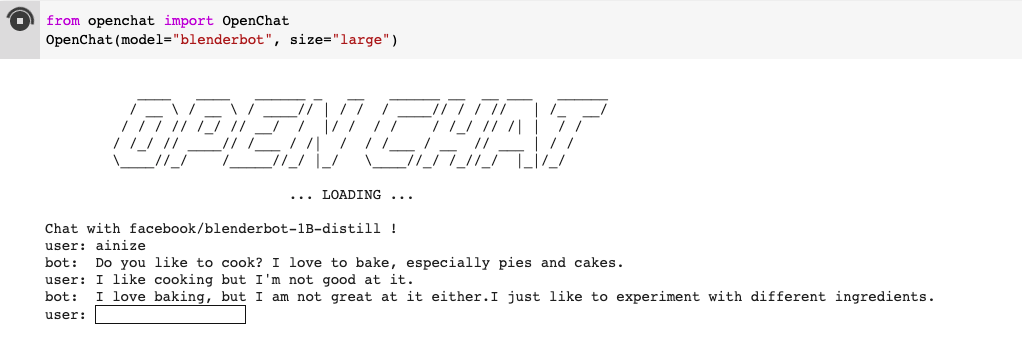
The execution environment was set to colab, and you can check it in here.
- Using Ainize’s Open chat DEMO
This time, I will run Open chat through the Open chat DEMO provided by Ainize without installing Open chat.

After entering the demo page, you can complete the nickname creation and you are ready to go. After that, if you press the Send button after writing the desired word, the entered word is sent and the answer is returned. The DEMO used above can be used in here.
- Using Ainize’s Open chat API
This time, we will use Open chat using the openchat API provided by Ainize. If you want to use Open chat in other services, this method will be convenient! Open chat uses POST method,
curl -X POST “https://main-openchat-fpem123.endpoint.ainize.ai/send/{User’s nickname}” -H “accept: application/json” -H “Content-Type: multipart/form-data” -F “text={Message you want to send}”
You can call it in the same way. After that, if you wait for a while
{“output”:” I am a teacher as well, I love my job. What kind of work do you like?”}
You can get a response like More details can be found here.
Chatbot present and future
Currently, the use of chatbots impacts only a small fraction of our daily life. There are two reasons for this. First, the chatbot doesn’t fully understand what people are saying as the human conversation is very complex. Not just because you understand the meaning of words, you can communicate, but you also need to understand the context and intent of the conversation. It is very difficult for artificial intelligence to learn complex conversational methods for humans like this. Second, there is not enough data to train a chatbot model. A famous saying among people working with artificial intelligence is “GIGO” (Garbage-In, Garbage-Out). This means that if you train with poor quality data, you will get poor quality predictions. In order to improve the performance of chatbots, high-quality data is required, however this is not something that can always be achieved.
Although, if these problems are improved, chatbots will be more likely to be used in more fields than they are now. One of the areas where chatbots will be used in the future is education. For example, when seeking information most people tend to be ashamed of asking for help. Perhaps the reason you haven’t tried to get help from someone is because you might hear a response similar to “Can’t you do this?” when you tried to get help before. But chatbots don’t provide this type of answers. This is probably where chatbots may outperform humans in terms of education. Machines cannot evaluate or judge people so no matter how many times you ask the same question, the chatbot will give you the same answer without complaining. With time the chatbot’s performance will improve and if you take advantage of the characteristics and answers of the chatbot its usefulness in the field of education will increase.
We haven’t reached this level of perfection yet but if the technology of artificial intelligence is more advanced than it is now and robots can comprehend 100% of human words with accuracy, artificial intelligence may go beyond making human life easier and perhaps robots may become our friends.
This article was written using a model that is based on common interests in the community. Can you easily tell whether this was written by a human or a machine? Let’s find out with the next article. Thanks for reading!